-
R 로 좋아하는 노래가사( lyrics ) 텍스트 마이닝 ( text mining ) 하기 + 의미연결망 분석(Semantic Network Analysis)R + Textmining (텍스트마이닝) 2020. 2. 20. 14:13

출처 : mnet 필요 라이브러리(library)
-
library(base64enc)
-
library(arules)
-
library(KoNLP)
-
library(NIADic)
-
library(RmecabKo)
-
library(tidyverse)
-
library(igraph)
#### 의미연결망 (Semantic Network Analysis)란?
언어 네트워크 분석이라고도 하는 의미연결망 분석은 사회현상을 탐구하는 데 있어 행위자들의 관계 구조를 통해 특징을 밝혀내는 사회연결망 분석(Social Network Analysis)를 활용한 기법으로 행위자의 대상이 아닌 그들의 언어를 분석하여 단어간의 상호작용 관계 구조를 분석하는 것을 말합니다 (출처 : 빅데이터 관련 신문기사의 의미연결망 분석_최윤정, 권상희)
굉장히 어려울 수도 있는 설명입니다만 쉽게 말해 텍스트의 구조를 밝혀내어 어떤 텍스트가 강한 영향을 가지는지 파악하고 텍스트간의 관계를 파악하는데 그 목적이 있는 분석 기법이라고 할 수 있겠습니다
#### KoNLP 사전작업
install_mecab("C:/Rlibs/mecab")
devtools::install_github('haven-jeon/NIADic/NIADic', build_vignettes = TRUE)
Sys.setenv(JAVA_HOME='C:/Program Files/Java/jre1.8.0_241')
buildDictionary(ext_dic = "woorimalsam")
useNIADic()#### 텍스트 파일 불러오기
fiesta <- readLines("D:/fiesta.txt")
텍스트 파일을 불러올때 많이 하는 실수입니다. 텍스트가 있는 마지막 줄에서 엔터(Enter)를 눌러 커서를 밑으로 내려서 제일 왼쪽에 위치시켜야 R로 불러올 때 오류가 나지 않습니다. 왜 그런지 아시는 분은 아직 만나뵙지 못했습니다... 저도 궁금하더군요,
#### 한글 - 품사별 처리
fiesta <- fiesta %>% SimplePos09() fiesta에 SimplePos09( )를 적용하여 품사별로 뽑아냅니다
개인적으로 extraNoun, nouns보다는
품사별 추출이 가능한 SimplePos09를 선호합니다
아래는 SimplePos09와 SimplePos22에 대한 인포그래픽입니다

출처 : KAIST 품사 태그셋 #### 데이터 셋 만들기
fiesta <- fiesta %>%
melt() %>%
as_tibble() %>%
select(3,1) ## 3열과 1열 추출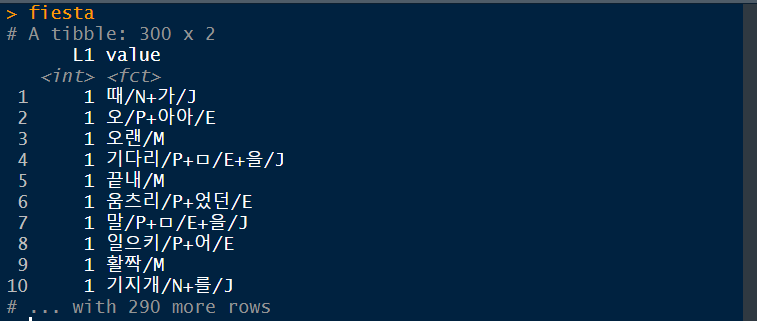
SimplePos09( )로 추출한 단어를 데이터 셋으로 만들어 봅시다
#### 명사 용언 수식언만 추출하기
## 명사 추출
fiesta_명사 <- fiesta %>%
mutate(명사=str_match(value,'([가-힣]+)/N')[,2]) %>% ## "명사" variable을 만들고 한글만 저장na.omit() %>% ## ([가-힣]+)/P') 한글 중 용언(P)만을 선택하는 정규표현식
mutate(글자수=str_length(명사)) %>% ## "글자수" variable을 만듭니다
filter(str_length(명사)>=2) ## 2글자 이상만 추려냅니다

## 용언 추출
fiesta_용언 <- fiesta %>%
mutate(용언=str_match(value,'([가-힣]+)/P')[,2]) %>% ## "용언" variable을 만들고 한글만 저장
na.omit() %>% ## ([가-힣]+)/P') 한글 중 용언(P)만을 선택하는 정규표현식mutate(글자수=str_length(용언)) %>% ## "글자수" variable을 만듭니다
filter(str_length(용언)>=2) ## 2글자 이상만 추려냅니다
## 수식언 추출
fiesta_수식언 <- fiesta %>%
mutate(수식언=str_match(value,'([가-힣]+)/M')[,2]) %>% ## "수식언" variable을 만들고 한글만 저장
na.omit() %>% ## ([가-힣]+)/M') 한글 중 수식언(M)만을 선택하는 정규표현식
mutate(글자수=str_length(수식언)) %>% ## "글자수" variable을 만듭니다
filter(str_length(수식언)>=2) ## 2글자 이상만 추려냅니다
#### 품사 추출 파일을 모아 데이터 프레임(Data Frame)으로 만들기
fiesta_의미 <- bind_rows(fiesta_명사,
fiesta_용언,
fiesta_수식언)View(fiesta_의미) 데이터 프레임을 확인합시다



#### 품사별 추출
fiesta_의미_명사 <- fiesta_의미 %>%
select(3, 1) %>% ## 3열(명사)과 1열 추출
na.omit()fiesta_의미_용언 <- fiesta_의미 %>%
select(5, 1) %>% ## 5열(용언)과 1열 추출
na.omit()fiesta_의미_수식언 <-fiesta_의미 %>%
select(6, 1) %>% ## 6열(수식언)과 1열 추출
na.omit()#### 품사별 글자수를 "단어"로 통합
fiesta_의미_명사 <- rename(fiesta_의미_명사,
c(단어 = 명사))## 명사, 용언, 수식언을 "단어"변수로 통합하기 위해 변수명 "단어"로 변경
fiesta_의미_용언 <- rename(fiesta_의미_용언,
c(단어 = 용언))## 명사, 용언, 수식언을 "단어"변수로 통합하기 위해 변수명 "단어"로 변경
fiesta_의미_수식언 <- rename(fiesta_의미_수식언,
c(단어 = 수식언))## 명사, 용언, 수식언을 "단어"변수로 통합하기 위해 변수명 "단어"로 변경
fiesta_의미_단어 <- bind_rows(fiesta_의미_명사,
fiesta_의미_용언,
fiesta_의미_수식언)## 변경한 변수명 "단어"로 기준으로 통합
그럼 데이터 프레임을 확인합시다

#### 그래프 그리기
단어_의미df <- fiesta_의미_단어 %>% graph_from_data_frame()
## igraph 형태에 맞게 데이터프레임을 변환합니다. 감이 안오신다면 결과를 확인하면 됩니다

[1]행 기지개 -> 1은
"기지개"를 1행에서 추출하였다는 뜻입니다
V(단어_의미df)$type <- bipartite_mapping(단어_의미df)$type
## bipartite_mapping( )함수는 양자간(TRUE / FALSE)로 구성하는 그래프를 그려주는 함수입니다
## V( ) 함수는 vertex sequence를 생성하는 함수입니다. vertex의 사전적 의미는 "꼭짓점"인데, 그래프에서 확인할 수 있습니다
## matrix로 변환
단어_의미m <- as_incidence_matrix(단어_의미df ) %*% t(as_incidence_matrix(단어_의미df)) ## matrix로 변환 합니다 matrix를 확인합시다
View(단어_의미m) 
matrix의 주대각선( [ i, i ]에 위치한 원소의 집합 )에 원소가 들어가 있습니다
이렇게 되면 의미연결이
기지개 -> 기지개
축제 -> 축제
이런식으로 나타납니다. 일종의 자기공선성 비독립적이라고 해야할까요. 적당한 말이 떠오르지 않는데..
아무튼 제대로된 단어간의 의미를 파악할 수 없습니다. 이를 "0"으로 처리합니다
## 주대각선을 "0"으로 처리
diag(단어_의미m) <- 0 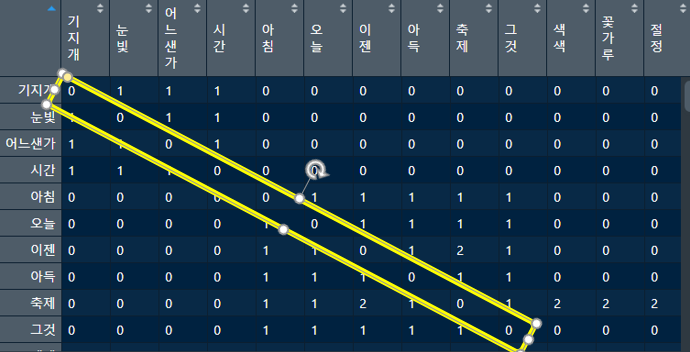
제대로 처리하였습니다
## 인접 행렬(adjacency matrix)로 변환
단어_의미m <- 단어_의미m %>% graph_from_adjacency_matrix() 인접행렬이 뭔지 잘 모르겠지만, 결과 값을 보면 이해될껍니다
결과를 확인합시다

이를 그래프로 시각화합니다
#### 시각화
단어_의미m %>% plot() 
3그룹의 단어 집단이 상당히 뭉쳐있습니다 잘 보이지 않네요;;(꽤 큰 크기로 저장했는데...)
좀 더 보기 편하게 다듬어 봅니다
단어_의미m %>%
as_tbl_graph() %>%
ggraph() +
geom_edge_link(aes(start_cap = label_rect(node1.name), end_cap = label_rect(node2.name))) +
geom_node_text(aes(label=name))
간단히 해석해봅시다
대부분의 단어가 가장 오른쪽 그룹은 "지금" "순간" "모든" "축제"를 기준으로 연결되어있습니다
왼쪽 중간 그룹은 관련 단어가 비교적 수평적으로 연결되어있군요
다음에는 감성분석(Sentiment Analysis)를 포스팅 하겠습니다
'R + Textmining (텍스트마이닝)' 카테고리의 다른 글
-