-
R 네이버 뉴스(Naver News) Selenium (셀레니움) + 기사 댓글R + Crawling (크롤링) 2020. 5. 8. 20:56

출처 : www.dinos.com 크롤링에 필요한 패키지(package)와 라이브러리(library)는 아래와 같습니다
install.packages(c("dplyr", "httr", "jsonlite", "rJava", "RSelenium", "stringr")
-
library(dplyr)
-
library(httr)
-
library(jsonlite)
-
library(rJava)
-
library(RSelenium)
-
library(stringr)
셀레니움(Selenium)을 실행해봅시다
https://r-pyomega.tistory.com/7?category=873554
R 크롤링 RSelenium (셀레니움) 을 크롬에서 구동하기
R에서 Selenium을 구동하려면 Java를 설치해야 합니다. Java설치는 https://r-pyomega.tistory.com/6 를 참고해주시길 바랍니다 Java설치 이후에 C드라이브에 r-selenium폴더를 만들어 아래 3파일을 다운 받습니다..
r-pyomega.tistory.com
## 링크 수집
각 언론사 링크가 아닌 네이버 뉴스에서 서비스하는 링크를 수집하겠습니다
방법은 이전 포스팅 <R 네이버 뉴스(Naver News) Selenium (셀레니움) + 기사 본문>을 참조해주십시요
https://r-pyomega.tistory.com/25
R 네이버 뉴스(Naver News) Selenium (셀레니움) + 기사 본문
크롤링에 필요한 패키지(package)와 라이브러리(library)는 아래와 같습니다 install.packages(c("dplyr", "httr", "jsonlite", "rJava", "RSelenium", "stringr") library(dplyr) library(httr) library(jsonlit..
r-pyomega.tistory.com
수집한 링크를 확인합니다

수집한 링크 구조가 다릅니다
1, 15, 29번째 링크는 https://news.naver.로 시작합니다
나머지 링크는 http://sports.news.naver.로 시작합니다
링크도 다른만큼 해당 링크의 페이지 구조도 다릅니다
각각에 대해 다른 코드를 짜야합니다
# news.naver case
우선 https://news.naver.로 시작하는 링크부터 크롤링을 하겠습니다
전체 링크에서 https://news.naver.가 포함된 링크만 뽑아냅니다
news.naver <- grep("https://news.naver",링크_nnews)
링크_news.naver <- 링크_nnews[news.naver]링크_news.naver %>% head()

댓글이 있는 4번째 링크를 타고 들어갑니다
remDr$navigate(링크_news.naver[4]) 
전체 댓글을 보기 위해서 <댓글 더보기>를 클릭하는 명령어를 실행합니다
body <- remDr$getPageSource()[[1]]
body <- body %>% read_html() # 현재 페이지를 읽어옵니다
Sys.sleep(time =1)
reply <- remDr$findElement("css", "span.u_cbox_in_view_comment")
reply$clickElement() # <댓글 더보기>를 클릭합니다
네이버 뉴스 서비스는 <더보기>를 누를때 마다 댓글을 20개씩 볼수 있습니다
만약 총 n개의 댓글을 수집하려면 <더보기> 버튼을 n/20 - 1번 눌러야합니다
이를 실행하는 명령어를 만듭니다
body <- remDr$getPageSource()[[1]]
body <- body %>% read_html()
for(j in 0:500){
tryCatch({
j <- j+1
more_reply <- remDr$findElement("css", "span.u_cbox_page_more")
more_reply$clickElement()
if (j==500) break() # <더보기>를 500번 시행합니다
Sys.sleep(time = 0.01) # <더보기>를 누르고 0.01초 쉽니다 그렇지 않으면 에러날 확률이 높으니 꼭 넣습니다
}, error = function(e) cat("불러올 수 없습니다!\n"))
}
Sys.sleep(time = 1)그리고 댓글을 수집합니다
수집한 댓글을 개수를 <댓글수>로 카운팅합니다
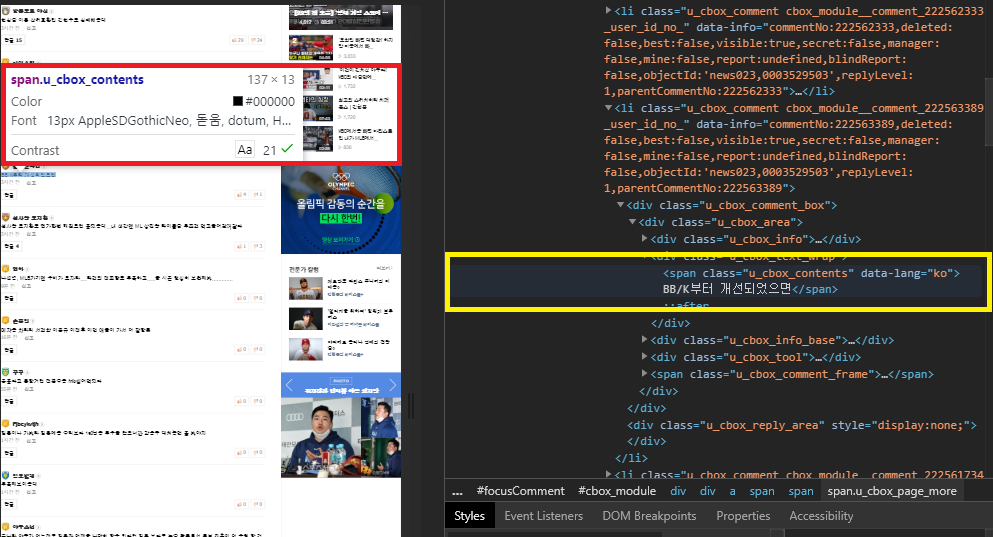
댓글_news.naver <- c() # 댓글을 담을 벡터 공간을 만듭니다
댓글수_news.naver <- c() # 댓글수를 담을 벡터 공간을 만듭니다
댓글.tmp1 <- body %>%
html_nodes("span.u_cbox_contents") %>%
html_text()
댓글수.tmp1 <- length(댓글.tmp1)
if (length(댓글.tmp1) != 0) {
댓글_news.naver <- append(댓글_news.naver, 댓글.tmp1)
} else {
댓글_news.naver <- append(댓글_news.naver, "수동확인")
}
if (length(댓글수.tmp1) != 0) {
댓글수_news.naver <- append(댓글수_news.naver, 댓글수.tmp1)
} else {
댓글수_news.naver <- append(댓글수_news.naver, "수동확인")
}결과를 확인합니다


기사페이지 주소도 따로 저장합니다
주소_news.naver.re <- c() # 주소을 담을 벡터 공간을 만듭니다
주소_news.naver.re <- append(주소_news.naver.re, 링크_news.naver[i])일련의 과정을 반복적으로 실행하는 for문 구조에 집어넣습니다
댓글_news.naver <- c()
댓글수_news.naver <- c()
주소_news.naver <- c()
for (i in 1:length(링크_news.naver)){
tryCatch({
remDr$navigate(링크_news.naver[i])
body <- remDr$getPageSource()[[1]]
body <- body %>% read_html()
for(j in 0:500){
tryCatch({
j <- j+1
more_reply <- remDr$findElement("css", "span.u_cbox_page_more")
more_reply$clickElement()
if (j==500) break() # <더보기>를 500번 시행합니다
Sys.sleep(time = 0.01) # <더보기>를 누르고 0.01초 쉽니다 그렇지 않으면 에러날 확률이 높으니 꼭 넣습니다
}, error = function(e) cat("불러올 수 없습니다!\n"))
}
Sys.sleep(time = 1)
댓글.tmp1 <- body %>%
html_nodes("span.u_cbox_contents") %>%
html_text()
댓글수.tmp1 <- length(댓글.tmp1)
if (length(댓글.tmp1) != 0) {
댓글_news.naver <- append(댓글_news.naver, 댓글.tmp1)
} else {
댓글_news.naver <- append(댓글_news.naver, "수동확인")
}
if (length(댓글수.tmp1) != 0) {
댓글수_news.naver <- append(댓글수_news.naver, 댓글수.tmp1)
} else {
댓글수_news.naver <- append(댓글수_news.naver, "수동확인")
}
주소_news.naver.re <- append(주소_news.naver.re, 링크_news.naver[i])
Sys.sleep(time = 1)
}, error = function(e) cat("불러올 수 없습니다!\n"))
}# sports.news case
sports.news case역시 news.naver. 경우와 흐름은 같습니다
일련의 과정을 반복적으로 실행하는 for문 구조에 집어넣습니다
sports.news <- grep("http://sports.news",링크_nnews)
링크_sports.news <- 링크_nnews[sports.news]
댓글_sports.news <- c()
댓글수_sports.news <- c()
주소_sports.news <- c()
for (i in 1:length(링크_sports.news)){
tryCatch({
remDr$navigate(링크_sports.news[i])
body <- remDr$getPageSource()[[1]]
body <- body %>% read_html()
for(j in 0:500){
tryCatch({
j <- j+1
more_reply <- remDr$findElement("css", "span.u_cbox_page_more")
more_reply$clickElement()
if (j==500) break() # <더보기>를 500번 시행합니다
Sys.sleep(time = 0.01) # <더보기>를 누르고 0.01초 쉽니다 그렇지 않으면 에러날 확률이 높으니 꼭 넣습니다
}, error = function(e) cat("불러올 수 없습니다!\n"))
}
Sys.sleep(time = 1)
댓글.tmp1 <- body %>%
html_nodes("span.u_cbox_contents") %>%
html_text()
댓글수.tmp1 <- length(댓글.tmp1)
if (length(댓글.tmp1) != 0) {
댓글_sports.news <- append(댓글_sports.news, 댓글.tmp1)
} else {
댓글_sports.news <- append(댓글_sports.news, "수동확인")
}
if (length(댓글수.tmp1) != 0) {
댓글수_sports.news <- append(댓글수_sports.news, 댓글수.tmp1)
} else {
댓글수_sports.news <- append(댓글수_sports.news, "수동확인")
}
주소_sports.news.re <- append(주소__sports.news.re, 링크_sports.news[i])
Sys.sleep(time = 1)
}, error = function(e) cat("불러올 수 없습니다!\n"))
}다음 포스팅은 다음뉴스를 크롤링 하겠습니다
'R + Crawling (크롤링)' 카테고리의 다른 글
R 네이버 뉴스(Naver News) Selenium (셀레니움) + 기사 본문 (0) 2020.05.07 R 크롤링 뽐뿌 (ppomppu) GET / POST (0) 2020.02.23 R 크롤링 뽐뿌 (ppomppu) GET / POST + Selenium (셀레니움) (0) 2020.02.23 R 크롤링 클리앙 (Clien) GET / POST 방식 (0) 2020.02.12 R 크롤링 클리앙(Clien) GET / POST + Selenium (셀레니움) (0) 2020.02.11 -